一、前述
根据前文中架构,本文我们讨论线下部分构建训练集部分。因为我们离线部分模型的选择是逻辑回归,所以我们数据必须有x和y.
二、具体流程
1.从数据库中分离出我们需要的数据。
用户行为表(日志)
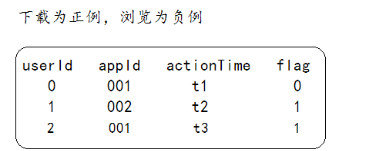
用户历史下载表

商品词表(商品的基本特征)

2.构建训练集中的关联特征
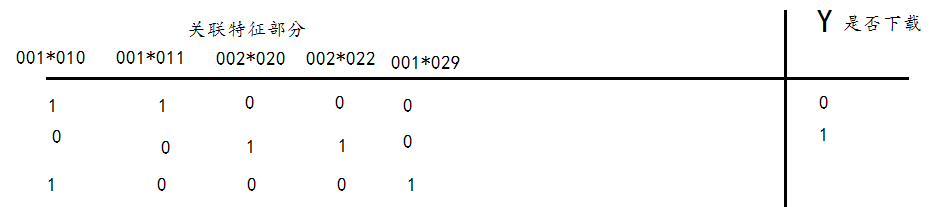
流程:

2.构建训练集中的基本特征

总结:注意特征名离散化因为如果特征不离散化会造成数据之间有关系。
三、具体构建过程
1、hive建表
真实的生产场景涉及到大概五十张表的字段,这里全部简化流程,直接给出最终的三张表:
应用词表:
CREATE EXTERNAL TABLE IF NOT EXISTS dim_rcm_hitop_id_list_ds( hitop_id STRING, name STRING, author STRING, sversion STRING, ischarge SMALLINT, designer STRING, font STRING, icon_count INT, stars DOUBLE, price INT, file_size INT, comment_num INT, screen STRING, dlnum INT)row format delimited fields terminated by '\t';
/** * *模拟app的商品词表 hitop_id STRING, 应用软件ID name STRING, 名称 author STRING, 作者 sversion STRING, 版本号 ischarge SMALLINT, 收费软件 designer STRING, 设计者 font STRING, 字体 icon_count INT, 有几张配图 stars DOUBLE, 评价星级 price INT, 价格 file_size INT, 大小 comment_num INT, 评论数据 screen STRING, 分辨率 dlnum INT 下载数量 */
用户历史下载表:
CREATE EXTERNAL TABLE IF NOT EXISTS dw_rcm_hitop_userapps_dm( device_id STRING, devid_applist STRING, device_name STRING, pay_ability STRING)row format delimited fields terminated by '\t';
/** *用户下载历史表 这里没有用户这个概念 手机设备ID就是userId * device_id STRING, 手机设备ID devid_applist STRING, 下载过软件列表 device_name STRING, 设备名称 pay_ability STRING 支付能力 */
正负例样本(用户当前行为即日志)表:
CREATE EXTERNAL TABLE IF NOT EXISTS dw_rcm_hitop_sample2learn_dm( label STRING, device_id STRING, hitop_id STRING, screen STRING, en_name STRING, ch_name STRING, author STRING, sversion STRING, mnc STRING, event_local_time STRING, interface STRING, designer STRING, is_safe INT, icon_count INT, update_time STRING, stars DOUBLE, comment_num INT, font STRING, price INT, file_size INT, ischarge SMALLINT, dlnum INT)row format delimited fields terminated by '\t';
/** * 正负例样本表 = 浏览记录+标签 label STRING, Y列,-1或1代表正负例 label值实际上是批处理得出来的,用户浏览了并在一段时间内下载为正例 device_id STRING, 设备ID hitop_id STRING, 应用ID screen STRING, 手机软件需要的分辨率 en_name STRING, 英文名 ch_name STRING, 中文名 author STRING, 作者 sversion STRING, 版本 mnc STRING, Mobile Network Code,移动网络号码 event_local_time STRING, 浏览的时间 interface STRING, designer STRING, is_safe INT, icon_count INT, update_time STRING, stars DOUBLE, comment_num INT, font STRING, price INT, file_size INT, ischarge SMALLINT, dlnum INT */
2、load数据
分别往三张表load数据:
商品词表:load data local inpath '/opt/sxt/recommender/script/applist.txt' into table dim_rcm_hitop_id_list_ds;用户历史下载表:load data local inpath '/opt/sxt/recommender/script/userdownload.txt' into table dw_rcm_hitop_userapps_dm;正负例样本表:load data local inpath '/opt/sxt/recommender/script/sample.txt' into table dw_rcm_hitop_sample2learn_dm;
3、构建训练数据
3.1创建临时表
创建处理数据时所需要的临时表CREATE TABLE IF NOT EXISTS tmp_dw_rcm_hitop_prepare2train_dm ( device_id STRING, label STRING, hitop_id STRING, screen STRING, ch_name STRING, author STRING, sversion STRING, mnc STRING, interface STRING, designer STRING, is_safe INT, icon_count INT, update_date STRING, stars DOUBLE, comment_num INT, font STRING, price INT, file_size INT, ischarge SMALLINT, dlnum INT, idlist STRING, device_name STRING, pay_ability STRING)row format delimited fields terminated by '\t';最终保存训练集的表CREATE TABLE IF NOT EXISTS dw_rcm_hitop_prepare2train_dm ( label STRING, features STRING)row format delimited fields terminated by '\t';
3.2 训练数据预处理过程
首先将数据从正负例样本和用户历史下载表数据加载到临时表中
INSERT OVERWRITE TABLE tmp_dw_rcm_hitop_prepare2train_dmSELECT t2.device_id, t2.label, t2.hitop_id, t2.screen, t2.ch_name, t2.author, t2.sversion, t2.mnc, t2.interface, t2.designer, t2.is_safe, t2.icon_count, to_date(t2.update_time), t2.stars, t2.comment_num, t2.font, t2.price, t2.file_size, t2.ischarge, t2.dlnum, t1.devid_applist, t1.device_name, t1.pay_abilityFROM( SELECT device_id, devid_applist, device_name, pay_ability FROM dw_rcm_hitop_userapps_dm) t1RIGHT OUTER JOIN( SELECT device_id, label, hitop_id, screen, ch_name, author, sversion, IF (mnc IN ('00','01','02','03','04','05','06','07'), mnc,'x') AS mnc, interface, designer, is_safe, IF (icon_count <= 5,icon_count,6) AS icon_count, update_time, stars, IF ( comment_num IS NULL,0, IF ( comment_num <= 10,comment_num,11)) AS comment_num, font, price, IF (file_size <= 2*1024*1024,2, IF (file_size <= 4*1024*1024,4, IF (file_size <= 6*1024*1024,6, IF (file_size <= 8*1024*1024,8, IF (file_size <= 10*1024*1024,10, IF (file_size <= 12*1024*1024,12, IF (file_size <= 14*1024*1024,14, IF (file_size <= 16*1024*1024,16, IF (file_size <= 18*1024*1024,18, IF (file_size <= 20*1024*1024,20,21)))))))))) AS file_size, ischarge, IF (dlnum IS NULL,0, IF (dlnum <= 50,50, IF (dlnum <= 100,100, IF (dlnum <= 500,500, IF (dlnum <= 1000,1000, IF (dlnum <= 5000,5000, IF (dlnum <= 10000,10000, IF (dlnum <= 20000,20000,20001)))))))) AS dlnum FROM dw_rcm_hitop_sample2learn_dm) t2ON (t1.device_id = t2.device_id); 选择右外关联的原因是因为以用户行为为基准。
这张表得到的数据就是关联特征中的数据,截图如下:
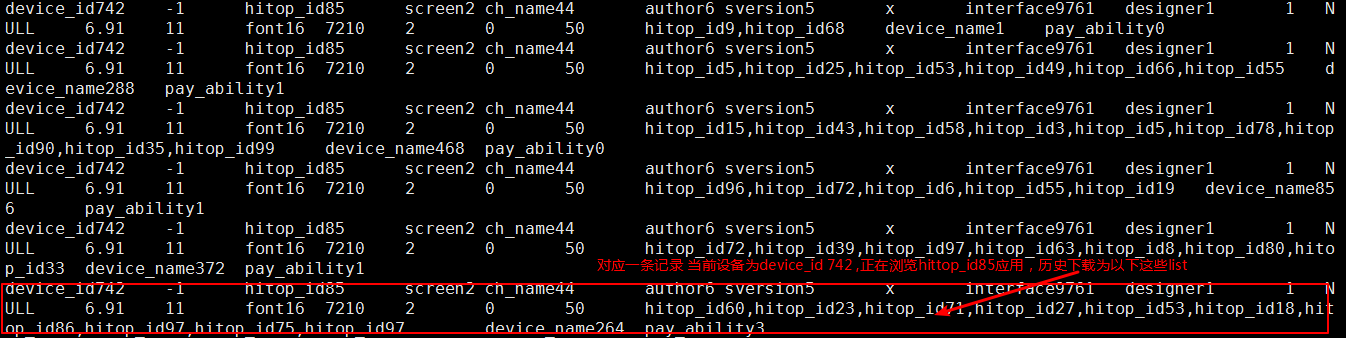

在hive中使用python脚本处理数据的原理:
Hive会以输出流的形式将数据交给python脚本,python脚本以输入流的形式来接受数据,接受来数据以后,在python中就行一系列的数据处理,处理完毕后,又以输出流的形式交给Hive,交给了hive就说明了就处理后的数据成功保存到hive表中了。INSERT OVERWRITE TABLE dw_rcm_hitop_prepare2train_dmSELECTTRANSFORM (t.*)USING 'python dw_rcm_hitop_prepare2train_dm.py'AS (label,features)FROM( SELECT label, hitop_id, screen, ch_name, author, sversion, mnc, interface, designer, icon_count, update_date, stars, comment_num, font, price, file_size, ischarge, dlnum, idlist, device_name, pay_ability FROM tmp_dw_rcm_hitop_prepare2train_dm) t;
python处理流程:
#! /usr/bin/env python# -*- coding: utf-8 -*-# ----------------------------------------------------------------------------# File Name: dw_rcm_hitop_prepare2train_dm.py# Copyright(C)Huawei Technologies Co.,Ltd.1998-2014.All rights reserved.# Describe: # Input: tmp_dw_rcm_hitop_prepare2train_dm# Output: dw_rcm_hitop_prepare2train_dmimport sysimport codecsimport randomimport mathimport timeimport datetimeif __name__ == "__main__": random.seed(time.time()) for l in sys.stdin: d = l.strip().split('\t') if len(d) != 21: continue # Extract data from the line label = d.pop(0) hitop_id = d.pop(0) screen = d.pop(0) ch_name = d.pop(0) author = d.pop(0) sversion = d.pop(0) mnc = d.pop(0) interface = d.pop(0) designer = d.pop(0) icon_count = d.pop(0) update_date = d.pop(0) stars = d.pop(0) comment_num = d.pop(0) font = d.pop(0) price = d.pop(0) file_size = d.pop(0) ischarge = d.pop(0) dlnum = d.pop(0) hitopids = d.pop(0) device_name = d.pop(0) pay_ability = d.pop(0) # Construct feature vector features = [] features.append(("Item.id,%s" % hitop_id, 1)) features.append(("Item.screen,%s" % screen, 1)) features.append(("Item.name,%s" % ch_name, 1)) features.append(("All,0",1)) features.append(("Item.author,%s" % author, 1)) features.append(("Item.sversion,%s" % sversion, 1)) features.append(("Item.network,%s" % mnc, 1)) features.append(("Item.dgner,%s" % designer, 1)) features.append(("Item.icount,%s" % icon_count, 1)) features.append(("Item.stars,%s" % stars, 1)) features.append(("Item.comNum,%s" % comment_num,1)) features.append(("Item.font,%s" % font,1)) features.append(("Item.price,%s" % price,1)) features.append(("Item.fsize,%s" % file_size,1)) features.append(("Item.ischarge,%s" % ischarge,1)) features.append(("Item.downNum,%s" % dlnum,1)) ####User.Item and User.Item*Item idlist = hitopids[:-2].split(',') idCT = 0; for id in idlist: features.append(("User.Item*Item,%s" % id +'*'+hitop_id, 1)) idCT += 1 if idCT >= 3: #取每一个用户的前3个下载历史进行关联,因为用户量比较多,所以这里最后结果覆盖还是比较全的。 break; features.append(("User.phone*Item,%s" % device_name + '*' + hitop_id,1))#升维 features.append(("User.pay*Item.price,%s" % pay_ability + '*' + price,1)) # Output output = "%s\t%s" % (label, ",".join([ "%s:%d" % (f, v) for f, v in features ]))#这里join相当于是把list中的数据进行拆分,然后添加上分号。 print output
经过上述处理之后的数据如图所示:

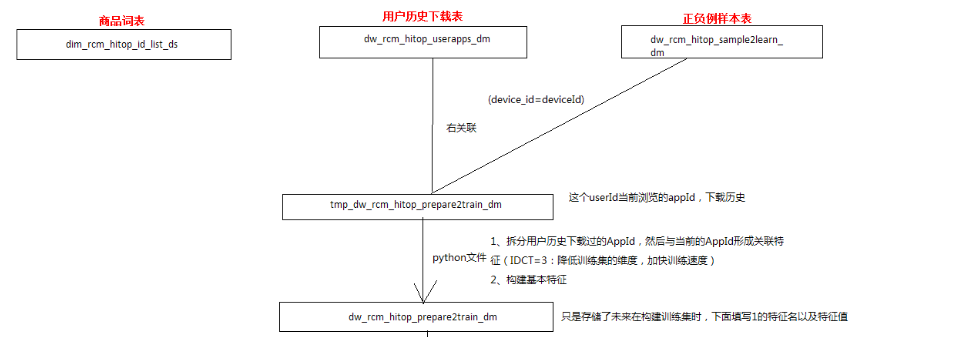
特征工程部分前期准别结束。